Summary
At 11:00 CEST on Sunday 16 of June 2024 the Mainnet blockchain stopped producing blocks.
The stall was caused by a bug in the node software which prevented nodes from tallying timeout messages and creating a timeout certificate. Without this certificate nodes did not progress as expected by the consensus protocol.
The issue was resolved by deploying a node with a corrected tallying process. The node created the missing timeout certificate and propagated it to other nodes. This allowed the network to resume normal operation.
At no point in time was safety violated, i.e., up-to-date nodes always agreed on the state of the blockchain. The resolution of the incident did not require any rollback, that is no finalized transactions were reverted. Transaction that were submitted (but were not finalized) during the downtime may have to be resubmitted.
The normal state of operation was restored around 20:00 CEST of the same day.
Impact
No blocks were produced starting from 11:00 CEST until the fixed node produced a timeout certificate which resumed normal operations (around 19.51 CEST).
Safety of the blockchain was never violated and no transactions were reverted over the course of the incident. Transactions that were submitted between 11:00 and 20:00 CEST may not have been included in blocks and therefore should be resubmitted.
We have no overview of the missing transactions that might have impacted the transaction rewards for validators.
Detection
The incident was detected by Concordium chain monitoring at 11.08, an alert was sent to the Concordium on-call duty engineers.
Root Cause
The following is a deep dive into the root cause of the incident.
Consensus Primer
This section provides a (simplified) overview on the consensus layer.
Block Production and Timeouts
The protocol proceeds in rounds. In each round a chosen validator will produce a block which is then signed by the other validators. These signatures, or more precisely at least 2/3 of them (weighted by stake), form a quorum certificate (QC). Once a QC exists, the next round can start.
However, if the block production takes too long, validators will start to sign timeout messages. Enough of them (at least 2/3 in terms of stake) allow any validator to create a timeout certificate (TC). Once a TC exists the next round can start.
A block is considered final if it has a direct descendant in the next round with a QC. A final block also finalizes any block before it.
Epoch Transition and Paydays
The protocol execution is divided into epochs to allow for stake changes. These roughly follow real time (1 hour per epoch). To transition to the new epoch, a party must see a finalized block after the nominal end of the epoch.
Every 24th epoch the first block in the epoch is the payday block in which validation rewards are distributed. Computing this block is costly. This increases the likelihood of timeouts when creating this block.
Failed Timeout at Payday

The issue started at the beginning of epoch
6360 when validator tried to create the payday block.In the first attempt a validator tried to create payday block in round
10813905 and epoch 6360 . The block was propagated, and at least 2/3 of validators signed it. But due to the amount of time needed to create the special payday block, many validators timed out while waiting to receive the signatures, and started propagating timeout messages. Certain validators saw 2/3 signatures on the block and progressed to round 10813906 with a QC, other validators saw 2/3 timeouts and progressed to round 10813906 with a TC. This is the expected behavior of the consensus protocol.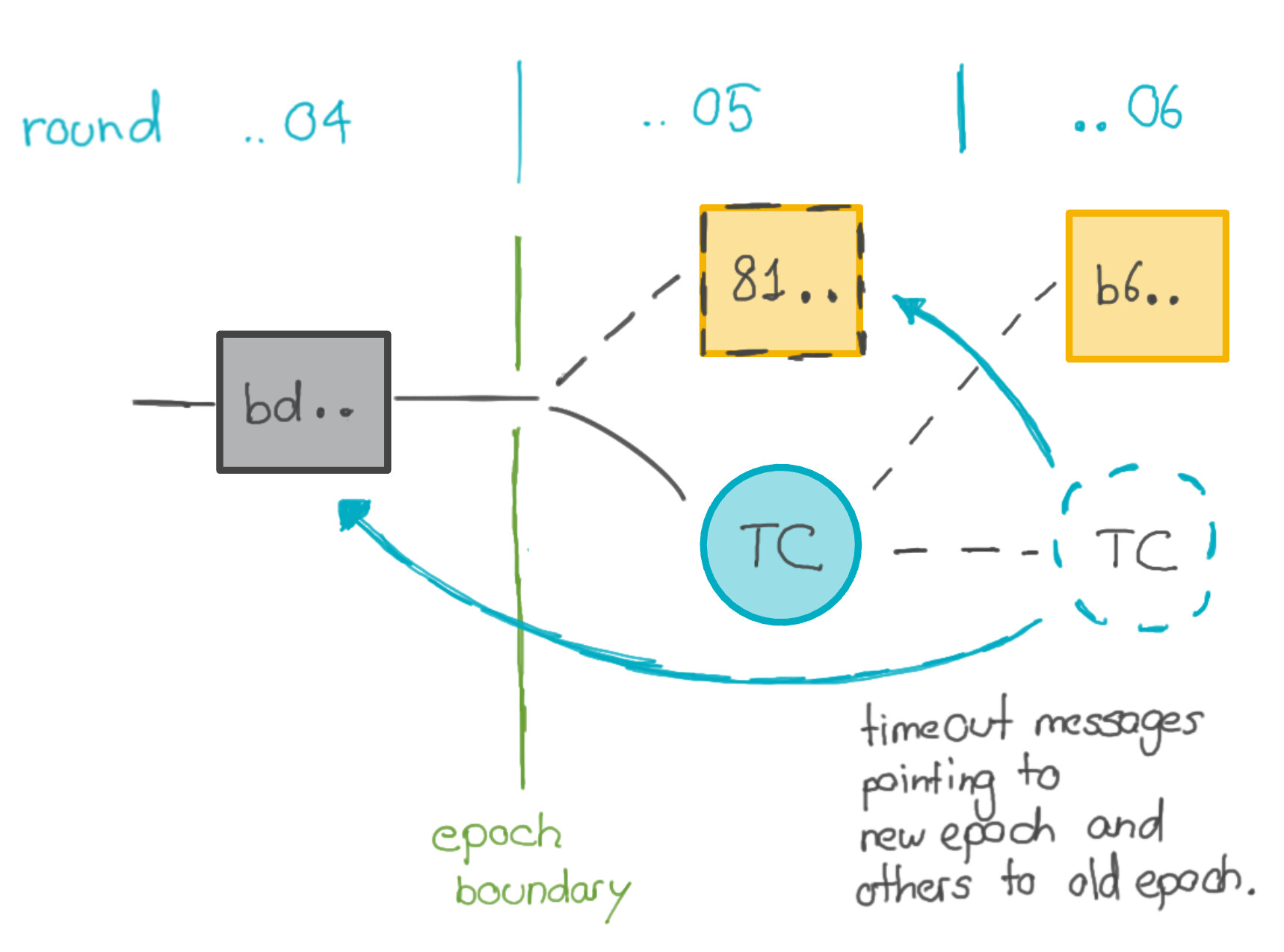
In round
10813906, another validator created another first block for epoch 6360. But because this validator progressed with a TC, it started making the block late, and most validators timed-out before signing this block. (Once a node has timed-out, it cannot subsequently sign a block in that round, so no QC could be generated.) More than 2/3 of all validators (in terms of stake) sent timeout messages in round 10813906, enough to create a timeout certificate. However, some of these validators pointed to block 81.. in round 10813905 as their best block (those that progressed with a QC), others pointed to block bd.. in round 10813904 as their best block (those that progressed with a TC). This is again the expected behaviour of the consensus protocol.
Due to a bug in the software, adding up the weights of the timeouts pointing to blocks in different epochs did not give the correct value, so the nodes failed to realize that they had enough time out messages, and did not create the timeout certificate.
Triggering the bug required a specific set of rare conditions to hold which may explain why we have not seen this happen before on mainnet or testnet.
Resolution
Once the root cause had been identified the network could be restored as follows.
First, a new node build was created where the tally bug was fixed.
A node with the fixed build was deployed on mainnet. The node was able to collect the timeout messages and then to create a timeout certificate (TC) for round 10813906. The TC was propagated to other nodes by means of catch-up. Once validators had seen the TC, they progressed to the next round which restored normal operations.
As a next step the hot-fix will be publicly released.
Concordium Team